Last time we have skimmed through neural networks. Today I’d like to describe one cool algorithm that is based on them.
Up until now we have worked on character recognition in images. It’s quite straightforward to convert an image to numbers, we just take pixel intensities and we have numbers. But what to do if we want to work with text? We can not do matrix multiplication with words, we need to somehow convert them to numbers. One way to do it is just take all words and number them. ‘aardvark’ would be 1, ‘aardwolf’ 2 etc. The problem with this approach is that similar words would have completely different numbers. Let’s say you are working on image recognition. You want to have a model that says “This is most likely a cat, but maybe it’s a kitten or a tiger. It definitely is something cat-like”. For this it’s better to have numeric representations of cat, kitten and tiger that are similar. Since we are dummies, I will not try to find mathematical reasons for this. Intuition tells me that pictures of kitten and cat are quite similar so it makes sense that output of the learning algorithm should be similar as well. It’s much harder to teach it if cat has number 10 and kitten 123,564.
But how to get such representations? We can use word2vec which allows us to map words to a n-dimensional vector space in a way that puts similar words together. The trick is quite simple. Similar words are used in similar contexts. I can say “I like pizza with cheese”. Or “I like hamburger with cheese”. Here the contexts are similar, just the food is different. Now I just need some algorithm that would read lot of text and somehow find words that are used in similar contexts and put them together.
Word2vec takes a neural network and teaches it to guess contexts based on words. As an input I can take a word “pizza” and try to teach the network to come up with “I like … with cheese”. This approach is called skip-gram. Or I can try the other direction and teach the network to answer “pizza” if I feed it “I like … with cheese.” This direction is called CBOW. There are some differences in the results, but thay are not important enough for now. In the next text I will describe skip-gram with 4 words in the context.
Let’s take a look at the details. We will take simple neural network with one hidden layer. On the input, I will use one-hot encoding. ‘aardvark’ would be [1,0,0,…], ‘aardwolf’ [0,1,0,…], each word would be represented by a vector with zeros and one ‘1’. If my dictionary has 50k words I would end up with 50k-dimensional input vector. We have the input, let’s move to the hidden layer. The size of the hidden layer is up to me, at the end it will be the size of the vector representing the word. Let’s pick 128. Then there will be an output layer that would map the data back to one-hot encoded vector of context words. The network will take large sparse vector, squeeze it into much smaller and denser one and then unsqueeze it to a large vector again.
I take “pizza”, convert it to a 50k-dimensional vector with only one nonzero value. Then I multiply this vector with 128x50k-dimensional matrix and I get 128-dimensional vector. I take this vector, multiply it with another 50k x128-dimensional matrix and get 50k dimensional vector. After the right normalization, this vector will contain probability that given word occurs in context of word “pizza”. Value on the first position will be quite low, aardvark and pizza are not usually used in the same sentence. Actually, I just did that, so the next time this text gets to a learning algorithm, the first value in the vector will be slightly larger.
Of course I have to somehow get those matrices, but it’s just neural network training with some dirty tricks to make it computable. The trouble is, that the dictionary can by larger than 50k words so the learning phase is not trivial. But I am a dummy, I do not care. I just need to know that I will feed it the whole internet (minus porn) and it will somehow learn to predict the context.
Ok, we have a neural network that can predict the context, where do I get the vectors representing the words? They are in the first matrix from the model. That’s the beauty of it. Imagine that I have “pizza” on the input. It’s a vector with all zeros and one “1”. The matrix multiplication is not a multiplication at all, it just picks one column of the first matrix in the model. One column is just 128-dimensional vector and when we multiply it with the second matrix we want to get probabilities that given word is in the context. I guess that “like”, “eat”, “dinner”, “cheese” or “bacon” will be quite high. Now let’s feed in “hamburger”. It will pick another column from the first matrix, but we expect similar words in the result. Not the same, but similar. And to get similar results, we need similar vector in the hidden layer so when we multiply it with the second matrix we get similar context words. But the vector in hidden layer is just a column in the first matrix. It means, that in order to get similar results for words with similar contexts, the columns in the first matrix have to be similar (well they do not have to, but it usually ends up this way)
It’s quite beautiful and powerful algorithm. What’s more, the positions of the vectors in the vector space have some structure too. You have most likely seen the example where they take vector for “king” subtract vector for “man” and add vector for “women” and they get dangerously close to vector for “queen”. I have no idea why it works this way, but it does.
That’s all for today, next time I will try to show you some results. Here is some visualization you can admire in the meantime.
Sources:
Tensorflow tutorial
Nice (long) lecture about word2vec details
Visualization of High Dimensional Data using t-SNE with R
Just Google the rest
 , multiplying it by matrix
, multiplying it by matrix  and adding some constant bias term
and adding some constant bias term  . In our letter recognition example
. In our letter recognition example  and pick the row with the maximal value. Index of the row is our class prediction.
and pick the row with the maximal value. Index of the row is our class prediction. We can again multiply it by another matrix and add another bias
We can again multiply it by another matrix and add another bias  We then can take the result of this second operation and use it as our prediction.
We then can take the result of this second operation and use it as our prediction. . It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of
. It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of  where
where  is the activation function. Popular choices are
is the activation function. Popular choices are  . If
. If  , we get positive value from the equation and the point is in one segment (class). If
, we get positive value from the equation and the point is in one segment (class). If  , the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:
, the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:  . When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy
. When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy . If we use vectors
. If we use vectors  and
and  . But how to get those parameters (a.k.a weights)
. But how to get those parameters (a.k.a weights)  as follows.
as follows.  if it’s a positive example and
if it’s a positive example and  if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set
if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set  which returns numbers between zero and one.
which returns numbers between zero and one. for each pair
for each pair  training examples:
training examples:  . If the sum is large, our model is bad and if the sum is 0 our model is the best. Function
. If the sum is large, our model is bad and if the sum is 0 our model is the best. Function  is function of parameters
is function of parameters ![y=[1,0,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-a0e86d8a3a87f26b4a05d78eb3eb9570_l3.png "Rendered by QuickLaTeX.com") for ‘A’,
for ‘A’, ![y=[0,1,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-84d443d2f327436b4938eb40576e15b0_l3.png "Rendered by QuickLaTeX.com") for ‘B’,
for ‘B’, ![y=[0,0,1,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-03ab8b923c19c48b62e4e5523373c8e2_l3.png "Rendered by QuickLaTeX.com") for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix
for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix 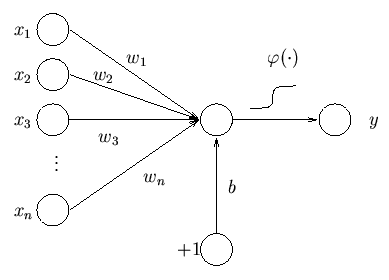
{kind=link}