Last time we have discussed word2vec algorithm, today I’d like to show you some of the results.
They are fascinating. Please remember that word2vec is an unsupervised algorithm, you just feed it a lot of text and it learns itself. You do not have to tell it anything about the language, grammar, rules, it just learns by reading.
What’s more, people from Google have published a model that is already trained on Google news, so you can just download the model, load it to you Python interpreter and play. The model has about 3.4G and contains 3M words, each of them represented as a 300-dimensional vector. Here is the source I have used for my experiments.
from gensim.models import Word2Vec
model = Word2Vec.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
# take father, subtract man and add woman
model.most_similar(positive=['father', 'woman'], negative=['man'])
[('mother', 0.8462507128715515),
('daughter', 0.7899606227874756),
('husband', 0.7560455799102783),
('son', 0.7279756665229797),
('eldest_daughter', 0.7120418548583984),
('niece', 0.7096832990646362),
('aunt', 0.6960804462432861),
('grandmother', 0.6897341012954712),
('sister', 0.6895190477371216),
('daughters', 0.6731119751930237)]
You see, you can take vector for “father” subtract “man” and add “woman” and you will get “mother”. Cool. How does it work? As we have discussed the last time, word2vec groups similar words together and luckily it also somehow discovers relations between the words. While it’s hard to visualize the relations in 300-dimensional space, we can project the vectors to 2D.
plot("man woman father mother daughter son grandmother grandfather".split())

Now you see how it works, if you want to move from “father“ to “mother“, you just move down by the distance which is between “man” and “woman”. You can see that the model is not perfect. One would expect the distance between “mother” and “daughter” will be the same as between “father” and “son”. Here it is much shorter. Actually, maybe it corresponds to reality.
Let’s try something more complicated
plot("pizza hamburger car motorcycle lamb lamp cat cow sushi horse pork pig".split())
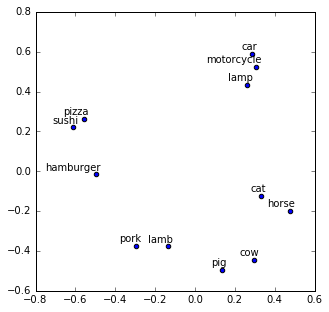
In this example, we loose lot of information by projecting it to 2D, but we can see the structure anyway. We have food on the left, meat in the middle, animals on the right and inanimate objects at the top. Lamb and lamp sound similar but it did not confuse the model. It just is not sure if a lamb it’s meat or an animal.
And now on something completely different – names.
plot("Joseph David Michael Jane Olivia Emma Ava Bill Alex Chris Max Theo".split())
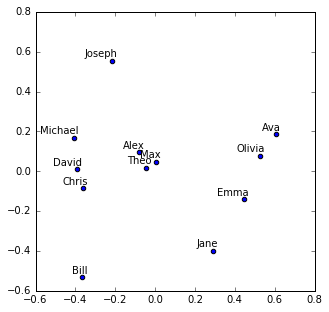
Guys on the left, gals on the right and unisex in the middle. I wonder, though what the vertical axis means.
I have played with the model for hours and it does not cease to surprise me. It just reads the text and learns so much, incredible. If you do not want to play with my code you can also try it online.
 , multiplying it by matrix
, multiplying it by matrix  and adding some constant bias term
and adding some constant bias term  . In our letter recognition example
. In our letter recognition example  and pick the row with the maximal value. Index of the row is our class prediction.
and pick the row with the maximal value. Index of the row is our class prediction. We can again multiply it by another matrix and add another bias
We can again multiply it by another matrix and add another bias  We then can take the result of this second operation and use it as our prediction.
We then can take the result of this second operation and use it as our prediction. . It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of
. It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of  where
where  is the activation function. Popular choices are
is the activation function. Popular choices are {kind=link}