Before we can start with neural networks, we should talk a bit more about Logistic Regression – without understanding Logistic Regression, we can not understand neural networks. Moreover, I have learned how to use math in WordPress so I need to try it.
As we already know, Logistic Regression tries to find linear hyperplane that separates two classes. Hyperplane is a thing that has one dimension less than the thing it is in. If we have 1-dimensional space (line), hyperplane is a one-dimensional point. If we have 3D space a hyperplane is a 2D plane. And if we have 784-dimensional space a hyperplane is a 783-dimensional space.
Let’s start with 1D example. We have a line and we want to separate it to two segments. We need to find or define one point that separates those two segments. We can define it like this  . If
. If  , we get positive value from the equation and the point is in one segment (class). If
, we get positive value from the equation and the point is in one segment (class). If  , the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:
, the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:  . When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy
. When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy
Generic definition of a hyperplane in n-dimensional space looks like this  . If we use vectors
. If we use vectors  and
and  , we can define hyperplane using vector multiplication
, we can define hyperplane using vector multiplication  . But how to get those parameters (a.k.a weights) ? We need to learn them form training samples.
. But how to get those parameters (a.k.a weights) ? We need to learn them form training samples.
First of all, we will define labels  as follows.
as follows.  if it’s a positive example and
if it’s a positive example and  if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set if the training example is an ‘A’. Now we need to be able to somehow compare output from and . The trouble is that is an unbounded real number and we need to somehow make it comparable to which is zero or one. That’s where we will use logistic function (hence the name Logistic Regression). The details are described here, for us dummies it suffices to say that Logistic Function maps real numbers to interval 0 to 1 in a way that is good. Like really good. It’s so good I will give it a name
if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set if the training example is an ‘A’. Now we need to be able to somehow compare output from and . The trouble is that is an unbounded real number and we need to somehow make it comparable to which is zero or one. That’s where we will use logistic function (hence the name Logistic Regression). The details are described here, for us dummies it suffices to say that Logistic Function maps real numbers to interval 0 to 1 in a way that is good. Like really good. It’s so good I will give it a name  . So now we have
. So now we have  which returns numbers between zero and one.
which returns numbers between zero and one.
Thanks to logistic function we can now compare results of our model with the training labels. Imagine that we have already obtained parameters , we can measure how well the parameters classify our training set. We just have to somehow calculate the distance from prediction. In ML the distance is called cost function. With linear regression people use cross-entropy and again, I will not go into details here. We just need to know that it returns 0 if our model classifies the sample correctly and some really really high number if it classifies it incorrectly.
If we put it together, we can calculate  for each pair and . If model makes correct prediction, the cost is zero, if it mis-predicts, the cost is high. We can even calculate a sum over all
for each pair and . If model makes correct prediction, the cost is zero, if it mis-predicts, the cost is high. We can even calculate a sum over all  training examples:
training examples:  . If the sum is large, our model is bad and if the sum is 0 our model is the best. Function
. If the sum is large, our model is bad and if the sum is 0 our model is the best. Function  is function of parameters , we have made our training samples and labels part of the function definition. Now the only thing we need is to find such so the function is as small as possible.
is function of parameters , we have made our training samples and labels part of the function definition. Now the only thing we need is to find such so the function is as small as possible.
And that’s how the model learns. We needed all those strange functions just to make this final function nice, having only one global minimum and other nice properties. While it’s possible to find the minimum analytically, for practical reasons it’s usually found by using something called gradient descent. I will not go to the details, it basically just generates random parameters , calculates and then it does small change to parameters so the next is a bit smaller. It then iterates until it reaches the minimum. That’s all we need to know for now.
Please note that we need all those strange functions mainly for learning. When classifying, I can still calculate and if it’s positive, it’s a letter ‘A’ and if it’s negative it’s some other letter. The advantage of applying the logistic function is that I can interpret the result as a probability.
What about multiple classes? We can use one-vs-all classifier. We can train a classifier that is able to separate A’s from the rest of the letters. Then B’s from the rest and so on. For our 10 letters we can apply the algorithm described above ten-times. Or we can use few tricks and learn all the letters in one pass.
The first trick is to change our labeling method. Before, we set y=1 if the letter in training set was an ‘A’. With multiple letters, we will use ![y=[1,0,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-a0e86d8a3a87f26b4a05d78eb3eb9570_l3.png "Rendered by QuickLaTeX.com") for ‘A’,
for ‘A’, ![y=[0,1,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-84d443d2f327436b4938eb40576e15b0_l3.png "Rendered by QuickLaTeX.com") for ‘B’,
for ‘B’, ![y=[0,0,1,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-03ab8b923c19c48b62e4e5523373c8e2_l3.png "Rendered by QuickLaTeX.com") for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix
for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix  and calculate the result using matrix multiplication
and calculate the result using matrix multiplication  (
( is 10-dimensional vector now as well). If we put weights for each letter to as a row, our matrix will have 10 rows (one for each letter) and 784 columns (one for each pixel). Our sample has 784 rows. If we multiply the two, we will get 10 numbers. We then element-wise add 10-numbers from and pick the largest one. That’s our prediction. For learning, we will use softmax function instead of logistic function, but the rest remains the same. At the end of the learning we will get 10×784 + 10 numbers that define 10 hyperplanes separating letters in 784-dimensional space.
is 10-dimensional vector now as well). If we put weights for each letter to as a row, our matrix will have 10 rows (one for each letter) and 784 columns (one for each pixel). Our sample has 784 rows. If we multiply the two, we will get 10 numbers. We then element-wise add 10-numbers from and pick the largest one. That’s our prediction. For learning, we will use softmax function instead of logistic function, but the rest remains the same. At the end of the learning we will get 10×784 + 10 numbers that define 10 hyperplanes separating letters in 784-dimensional space.
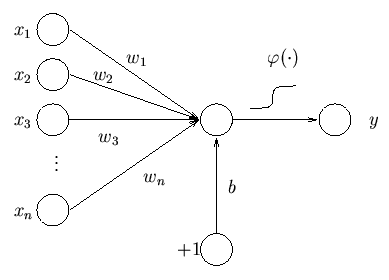
If case you are wondering why you need to know all of this, the reason is simple. Neural networks are built on top of ideas from logistic regression. In other words, logistic regression is one-layer neural network so in order to make real NN, we just need to add more layers. This is how our logistic regression looks like if depicted as a single neuron