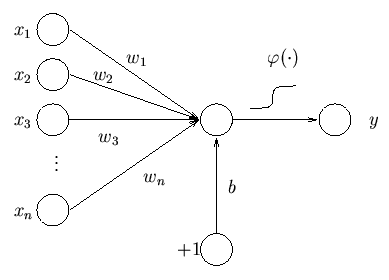
Even though Neural Networks are the most cool thing in machine learning, they conceptually are just multiple linear regressions chained one after the other. So I will not draw any fancy pictures of neurons, I will just write boring matrix multiplications. Both representations are equivalent.
Last time, we have learned that logistic regression classification is just matter taking sample  , multiplying it by matrix
, multiplying it by matrix  and adding some constant bias term
and adding some constant bias term  . In our letter recognition example is 784-dimensional vector, is 10×784 dimensional matrix and is 10-dimensional vector. Once our model learns weights and , we just calculate
. In our letter recognition example is 784-dimensional vector, is 10×784 dimensional matrix and is 10-dimensional vector. Once our model learns weights and , we just calculate  and pick the row with the maximal value. Index of the row is our class prediction.
and pick the row with the maximal value. Index of the row is our class prediction.
The downside of logistic regression is that it can only classify classes that are separable by linear plane. We can fix that by adding multiple linear regressions one after each other.
Let’s say that we take the input, multiply it by a matrix, add bias and then take the output.  We can again multiply it by another matrix and add another bias
We can again multiply it by another matrix and add another bias  We then can take the result of this second operation and use it as our prediction.
We then can take the result of this second operation and use it as our prediction.
We will call this Neural Network with one hidden layer. The hidden layer is the vector  . It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of will be. The size is usually called number of neurons in the hidden layer. We can even add more hidden layers, each with different size. Unfortunately no one will tell you how many layers and how big they should be, you have to play with the parameters and see how the network performs.
. It is hidden because nobody sees it, it’s just something internal to the model. It’s up to us to decide what the size of will be. The size is usually called number of neurons in the hidden layer. We can even add more hidden layers, each with different size. Unfortunately no one will tell you how many layers and how big they should be, you have to play with the parameters and see how the network performs.
To make things even more complicated, you can also use activation function. Activation function can take the result of each layer and make it more non-linear. So we will get  where
where  is the activation function. Popular choices are relu, tanh and for the last layer softmax.
is the activation function. Popular choices are relu, tanh and for the last layer softmax.
Luckily for us, it’s quite simple to play with neural networks in Python. There are several libraries, I have picked Keras, since it’s quite powerful and easy to use.
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.optimizers import SGD
model = Sequential()
# Hidden layer with 1024 neurons
model.add(Dense(output_dim=1024, input_dim=image_size * image_size, init="glorot_uniform"))
# ReLU activation
model.add(Activation("relu"))
# We have 10 letters
model.add(Dense(output_dim=10, init="glorot_uniform"))
# Softmax makes sense for the activation of the output layer
model.add(Activation("softmax"))
# Let the magic happen
model.compile(loss='categorical_crossentropy', optimizer=SGD())
model.fit(train_dataset, train_labels, batch_size=128, nb_epoch=50)
In this example we will create a neural network with one hidden layer of 1024 neurons with activation function ReLU. In other words (ignoring biases), we will take the pixels of the letter, multiply them by a matrix which will result in 1024 numbers. We will then set all the negative numbers to 0 (ReLU) and then multiply the result by another matrix to get 10 numbers. We then find the highest of those numbers. Let’s say that highest result is in second row then the resulting letter is B.
We of course need to train the network. It’s more complex, luckily we do not need to know much about it. So let’s just use Stochastic Gradient Descent with batch size 128. nb_epoch says that we should walk through all training examples 50-times. Please remember that training is just finding of the minimum of some loss function.
I am using Keras with Tensorflow so when I call model.compile it actually generates some optimized distributed parallel C++ code that can even run on GPU. The code will train the network for us. This is important, large networks with lots of hidden layers and lots of parameters can take ages and lot of calculations to learn. Keras and Tensorflow hides the complexity so I do not have to worry about it.
And what about the results? We get 96% accuracy on test set! Another 3% increase from SVM. Since the best result on notMNIS is allegedly 97.1% I think it’s not bad at all. Can you calculate how many parameters we do have? In the first layer we have matrix of 1024×784 parameters + 1024 bias terms. In the output layer we have 10×1024 + 10 parameters. In total it’s around 800,000 parameters. Training takes around 20 minutes on my laptop.
 . If
. If  , we get positive value from the equation and the point is in one segment (class). If
, we get positive value from the equation and the point is in one segment (class). If  , the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:
, the result is negative and the sample is in the other class. In 3D it’s similar, we just need more parameters:  . When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy
. When we plug-in our sample, we can again decide if the equation returns positive or negative value. Easy . If we use vectors
. If we use vectors  and
and  . But how to get those parameters (a.k.a weights)
. But how to get those parameters (a.k.a weights)  as follows.
as follows.  if it’s a positive example and
if it’s a positive example and  if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set
if it’s a negative one. We will only deal with two classes and cover multiple classes later. In our letter classification we will set  which returns numbers between zero and one.
which returns numbers between zero and one. for each pair
for each pair  training examples:
training examples:  . If the sum is large, our model is bad and if the sum is 0 our model is the best. Function
. If the sum is large, our model is bad and if the sum is 0 our model is the best. Function  is function of parameters
is function of parameters ![y=[1,0,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-a0e86d8a3a87f26b4a05d78eb3eb9570_l3.png "Rendered by QuickLaTeX.com") for ‘A’,
for ‘A’, ![y=[0,1,0,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-84d443d2f327436b4938eb40576e15b0_l3.png "Rendered by QuickLaTeX.com") for ‘B’,
for ‘B’, ![y=[0,0,1,...]^T](https://blog.krecan.net/wp-content/ql-cache/quicklatex.com-03ab8b923c19c48b62e4e5523373c8e2_l3.png "Rendered by QuickLaTeX.com") for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix
for ‘C’ etc. We also need to train different set of parameters (weights) for each letter. We can add all the weights into one matrix