V mé choré mysli se zrodil plán. V případě nedostatku vlastních myšlenek, jako například teď, vás budu oblažovat výběrem oblíbených kapitol z oblíbených knih. Takže se postupně budu vracet i ke knihám o kterých jsem už psal dříve, když jsem je četl.
Dnes budu psát o kapitole Prioritizing desirability, z knihy Agile Estimating and Planning Mika Cohena. Kapitola je o zjišťování toho, co si zákazník přeje. Začíná Kanovým modelem zákaznické spokojenosti. V principu jde o to, že existují tři základní kategorie vlastností produktu
- Nutné – vlastnosti, bez kterých se neobejde. Když kupuji notebook, chci aby měl monitor.
- Lineární – čím víc tím líp. Čím má notebook větší paměť, tím lépe.
- Vzrušující – věc kterou jsem nečekal a příjemně mě překvapí. U notebooku to může být například dálkové ovládání pro sledování filmu z postele.
Když si to zakreslíme do grafu, dopadne to asi takto
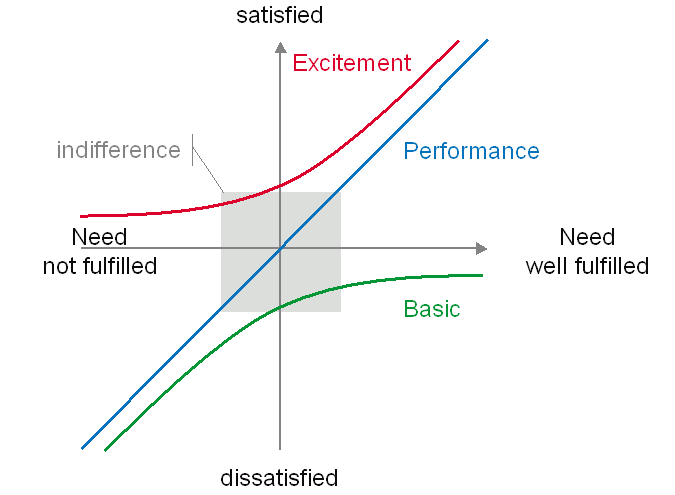
Na svislé ose máme spokojenost zákazníka. Nahoře je spokojený, dole nespokojený. Na vodorovné ose vidíme míru přítomnosti dané vlastnosti (nebo potřeby). Vlevo úplně chybí, vpravo je plně obsažena.
Zeleně jsou označeny nutné vlastnosti. Vidíme, že když nejsou obsaženy, tak zákazník dokáže být hodně nespokojený. Nicméně i když je do produktu přidáme, moc vysoko se na žebříčku spokojenosti nevyšplháme.
Modré jsou lineární vlastnosti. Ty jsou podle mě snadno pochopitelné.
Červeně jsou označeny vzrušující vlastnosti. Když nejsou obsaženy, zákazníka to moc neštve. Když je ale přidáme, můžeme si snadno zajistit jeho spokojenost.
Je důležité si uvědomit, že to samé rozdělení platí i u vlastností software. Když vyvíjíme agilně, můžeme toto rozdělení použít pro prioritizaci práce. Víme, že nutné vlastnosti musí náš produkt nutně obsahovat. Musíme je proto rozhodně stihnout do releasu, není dobré je odkládat. Nicméně nemusíme je implementovat plně. Vidíme, že nárůst spokojenosti není od určité úrovně naimplementování moc velký.
Lineární vlastnosti jsou druhé na řadě. Měli bychom jich stihnout co nejvíce v co největší míře. Nakonec je dobré přihodit pár vzrušujících vlastností, abychom si zákazníka trochu rozmazlili.
Otázkou zůstává, jak zjistit, do které kategorie daná vlastnost patří. I na to v knize dostaneme odpověď. Zeptáme se například následující otázkou, s možnými odpovědmi
Pokud váš nový program bude umět exportovat data do excelu
- Budu rád
- Čekám že to tak bude
- Je mi to jedno
- Zvládnu s tím žít
- Nebudu rád
Trik je v tom, že se ho zeptám ještě jednou na opak
Pokud váš nový program nebude umět exportovat data do excelu
- Budu rád
- Čekám že to tak bude
- Je mi to jedno
- Zvládnu s tím žít
- Nebudu rád
Když dostaneme odpověď na obě otázky, můžeme použít následující tabulku pro určení dané vlastnosti
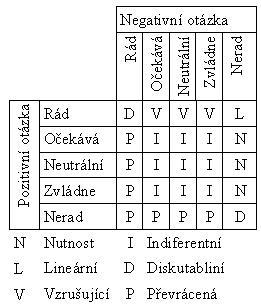
Teď už nám nic nebrání v tom, abychom se zeptali několika potencionálních uživatelů a podle toho určili, co vlastně od našeho produktu chtějí. Samozřejmě to nikdy nevyjde jednoznačně, ale s použitím statistiky nebo jiného podfuku to dokážeme zpracovat. Dostaname tak zajímavý nástroj na prioritizaci vlastností.
